Verbrauchsübersicht
Zur Verbrauchsübersicht gelangt man per Klick auf die Verbrauchsanzeige im oberen Bereich der Webseite. Diese Ansicht steht ausschließlich Administratoren zur Verfügung.

In der Verbrauchsübersicht werden die Verbrauchskosten und -informationen des aktuellen Monats angezeigt. Ausgehend vom gesamten zur Verfügung stehenden Budget werden unter anderem die folgenden Informationen angezeigt:
- Verbleibendes Budget
- Aktuelle Gesamtkosten
- Aufteilung der Verbrauchskosten nach Chat Token Verbrauch und Index Token Verbrauch
Darüber hinaus können die Verbrauchskosten je zugrunde liegendem Modell eingesehen werden.
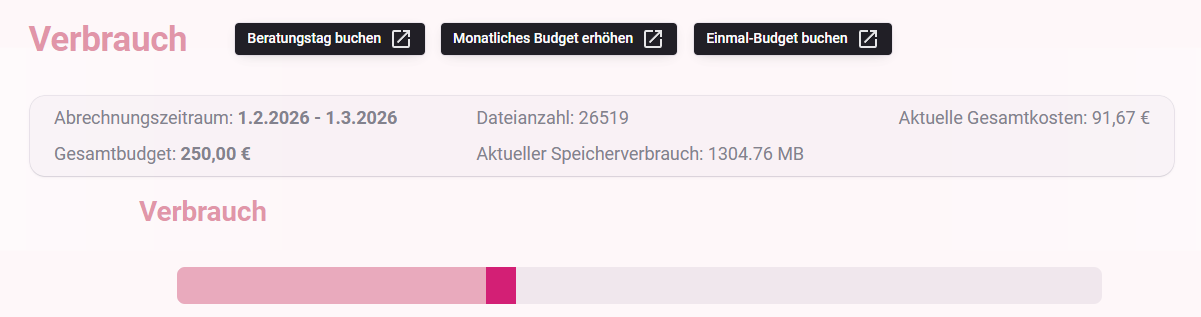
Zu einer weiteren detaillierten Ansicht der Verbrauchskosten gelangt man per Klick auf den Verbrauchsbalken.
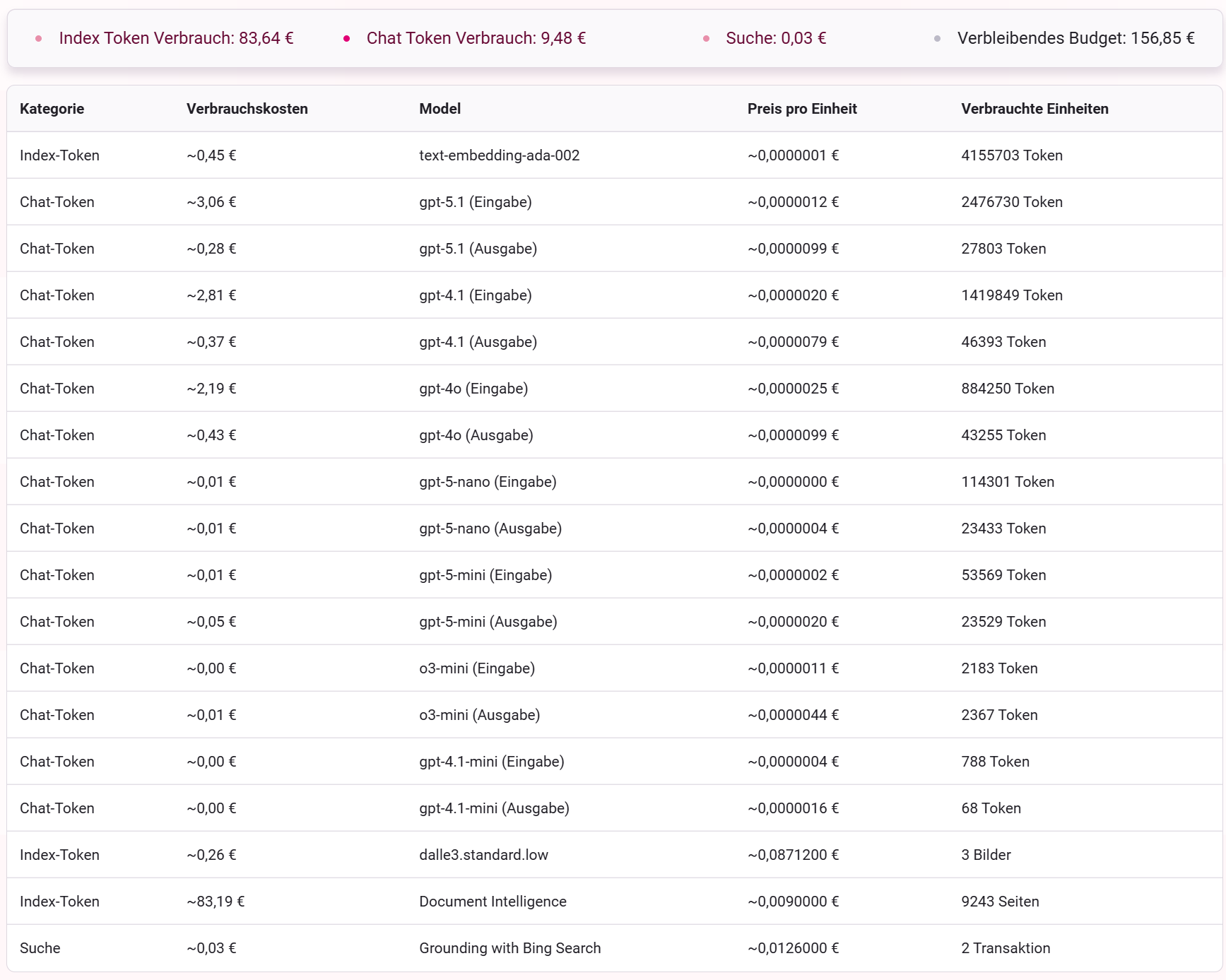
Verbrauchsdetails
Die Detailübersicht zeigt verschiedene Kategorien (Index-Token, Chat-Token, Suche). Je nach Nutzung von Business GPT entstehen Verbräuche.
Index-Token
Die Kategorie Index-Tokensetzt sich zusammen aus text-embeddingund Kosten für Document Intelligence. Kosten für Document Intelligenceentstehen immer dann, wenn Dokumente hochgeladen werden - direkt in den Chat oder in Dokumenten-Container. Dabei wird der Inhalt des Dokumentes extrahiert, womit pro extrahierte Seite Kosten entstehen. Embedding-Kosten entstehen immer dann, wenn Daten in einen (Dokumenten-) Container geladen werden. Dies ist der Fall beim Upload von Dokumenten in einen Container sowie bei der Anbindung von Datenquellen wie Jira, wo ebenfalls Daten in einen zugrundeliegenden Container geladen und dort gespeichert werden.
Embedding-Kosten entstehen hingegen nicht, wenn Dokumente in den Chat geladen werden, da diese Dokumente nicht in sogenannten Vektoren (im RAG) gespeichert werden.
Suche
Kosten für die Kategorie Sucheentstehen immer dann, wenn Sie Assistenten mit Internet Breakout (Websuche) verwenden. Für der Assistent eine Websuche durch fallen Kosten pro Suchanfrage an.
Chat-Token
Chat-Token werden auf zweierlei Art verbraucht: per Eingabe und per Ausgabe. Eingabe-Token werden immer dann verbraucht, wenn eine Anfrage an die KI gestellt wird, d.h. für jeden gesendeten Inhalt im Chatverlauf. Ausgabe-Token werden verbraucht, wenn die KI eine Antwort generiert. Auch hier gilt: Je mehr Text sowohl in der Eingabe als auch in der Ausgabe steht, umso höher sind die Verbrauchskosten.
Wichtig
Werden Dokumente direkt in den Chat hochgeladen, wird der gesamte Inhalt des Dokuments in der Anfrage an die KI/das Modell mitgesendet. Je mehr Inhalt das Dokument hat, umso größer ist der sogenannte Input und umso höher ist der Verbrauch von Eingabe-Token. 1 Token entspricht in etwa 4 Zeichen Text.
Budget nachbestellen
Neigt sich das monatliche Budget dem Ende oder ist es gänzlich aufgebraucht, kann Budget über den Telekom Cloud Marketplace für Geschäftskunden ganz einfach nachbestellt werden. Je nach Anforderung können dabei Tokens einmalig oder dauerhaft als zusätzliches monatliches Token-Budget geordert werden.
-
Einmaliges Budget
Buchen Sie einmaliges Zusatzvolumen über
-
Monatliches Budget
Buchen Sie monatliches Zusatzvolumen über